Contents
- Q&A: Common Questions in Data Science

Q&A: Common Questions in Data Science
Answering some of the most common questions asked at the Towards Data Science Team.
Introduction
Recently, Towards Data Science (TDS) launched a new column called “Ask Us Anything” which gives TDS readers the opportunity to ask any questions they have about Data Science to the team. In this article, I am going to answer some of the most common questions we have received so far.
One of the main reasons why there is so much interest in Data Science is its various applications. Data has always been a really important component in human history and making smart decisions based on past experiences and the information given can play a crucial role for either individuals or organizations.
Because of the interdisciplinarity of this subject (Figure 1), Data Science can be both a really exciting field to work in and also a daunting place to get started in. That’s why asking questions can come naturally in this habitat.
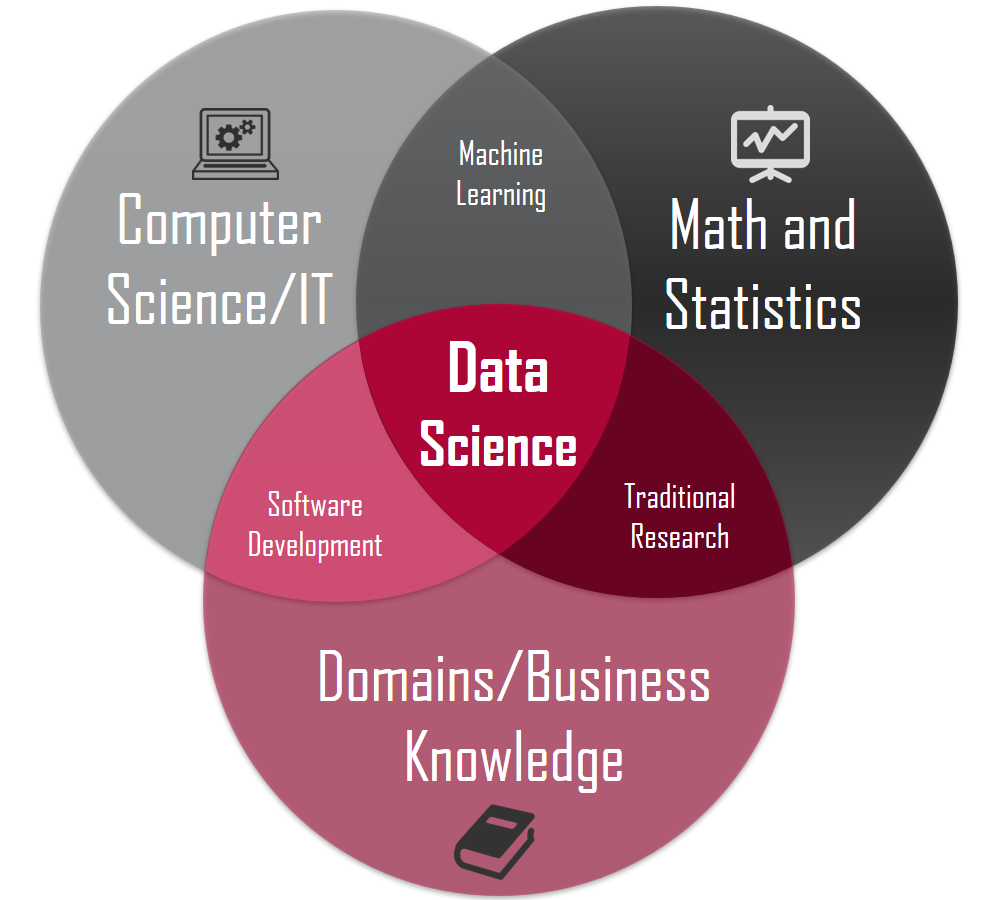 Figure 1: Data Science in summary. [1]
Figure 1: Data Science in summary. [1]
Readers Questions
How to get started in data science?
Getting started in a new field can always be unexpectedly a really exciting and scary experience at the same time. Fortunately, over the last few years, many free resources have been created in order to increase the public interest in Data Science. Some examples are:
- Online Courses: Google AI Education, Coursera: Machine Learning by Andrew Ng, etc…
- Books: Pattern Recognition and Machine Learning, by Christopher Bishop, An Introduction to Statistical Learning by Gareth James et al., etc…
- Online Publications: Towards Data Science!, Distill, No Free Hunch, etc…
- YouTube Channels: 3Blue1Brown, Arxiv Insights, Towards Data Science, Two Minute Papers, etc…
- Podcasts: DeepMind Podcast, TDS Podcast, etc…
After having gained the necessary background knowledge about Data Science, it is really important for beginners to get started with practical projects. If you are looking for some inspiration, Kaggle can be a great place to start.
How do I write a great data science article?
Once you have gained some knowledge in Data Science, it is a great idea to try to showcase some of the projects and topics you have researched. One of the easiest ways to do that is by writing articles either on your own personal website or for online publications (to reach a wider audience). If you are interested in writing for Towards Data Science, you can find more information and tips in this my previous article. Some main guidelines to write articles about Data Science are:
- Use GitHub Gists to share your code.
- Make use of free open data sources. In this way, it will become easier for the readers to test walkthrough examples.
- Make use of interactive data visualization tools to provide additional insights.
- Follow the curators’ guidelines!
What are some of the best options to identify which variables in a data set have
the most impact on a response variable?
Understanding which features bring more information in a data-analysis is a crucial task (especially when working with a large amount of data!). Some of the main benefits of reducing the number of features in a dataset are:
- Accuracy improvements.
- Overfitting risk reduction.
- Speed up in training.
- Improved Data Visualization.
- Increase in explainability of our model.
In order to reduce the number of features in a dataset, there are two main approaches; Feature Selection and Feature Extraction.
- Feature Selection: in Feature Selection we make use of different techniques such as the Filter/Wrapper/Embedded methods to choose which features to keep and which ones to discard from a dataset.
- Feature Extraction: in Feature Extraction, we instead reduce the number of features in a dataset by creating new features from the existing ones (and then discarding the original features). This can be done by using techniques such as Principal Component Analysis (PCA), Locally Linear Embedding (LLE), etc…
If you are interested in finding out more about Feature Selection and Feature Extraction techniques, more information is available here and here.
How do you take into consideration expert knowledge in your model?
Having a sound background knowledge of the data being analysed can be of great help when trying to decide which features to feed in a machine learning model for a prediction task.
For example, let us imagine we have a dataset with the departure, arrival time and distance travelled of different taxi trips and we want to predict the taxi fare for each of the different trips. Feeding in a Machine Learning model directly the departure and arrival times might not be the best idea since we would have to leave the ML model figure out what kind of relationship between these two features can be useful to predict the taxi fare. Using Expert Knowledge, we can instead first try to calculate the time difference between arrival and departure (by simply subtracting the two columns) and then feed in this new column (in conjunction with the travelled distance) into our model. This way, it is much more likely that our model will be able to perform better. The art of preparing raw features for Machine Learning analysis is typically called Feature Engineering.
If you are interested in finding out more about different Feature Engineering techniques, more information is available here.
How to get started with Robotic Process Automation (RPA)?
Robotic Process Automation (RPA) is a technology being developed to be used to automate manual tasks. What distinguishes RPA from traditional programming is its graphical user interface (GUI). RPA automation is performed by breaking down tasks performed by a user and repeating them. This technology can make programming easier for the automation of graphics-based processes. On average, robots can perform equivalent processes three times faster than humans and they are able to work every day of the year 24 hours a day. Some common examples of RPA companies are Automation Anywhere, UIPath and blueprism [2].
If you are planning to get started using RPA, UIPath Community Edition is freely available to download on Windows. Using UIPath, it is possible to implement complex workflows creating sequences and flowchart-based architectures. Each sequence/flowchart can then be composed of many sub-activities such as recording of a set of actions for the robot to perform or screen and data scraping instructions. Additionally, UIPath also enables error handling mechanisms in case of decision-making situations or the occurrence of unexpected delays between different processes.
In case you are looking for more information about RPA, you can have a look at my GitHub repository containing some examples or this my previous article.
Bibliography
[1] Data science concepts you need to know! Part 1,
Michael Barber. Accessed at: https://towardsdatascience.com/introduction-to-statistics-e9d72d818745
[2] Analytics Insight, Kamalika Some = https://www.analyticsinsight.net/top-10-robotic-process-automation-companies-of-2018/
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
