Contents
Photo by Riccardo Pelati on Unsplash
Answering Causal Questions in AI
Introduction to some of the most common techniques which can be used in order to query information from data for interpretable inference.
Introduction
Two of the main techniques used in order to try to discover causal relationships are Graphical Methods (such as Knowledge Graphs and Bayesian Belief Networks) and Explainable AI. These two methods form in fact the basis of the Association level in the Causality Hierarchy (Figure 1), enabling us to answer questions such as: What different properties compose an entity and how are the different components related each other?
In case you are interested in finding out more about how Causality is used in Machine Learning, more information is available in my previous article: Causal Reasoning in Machine Learning.
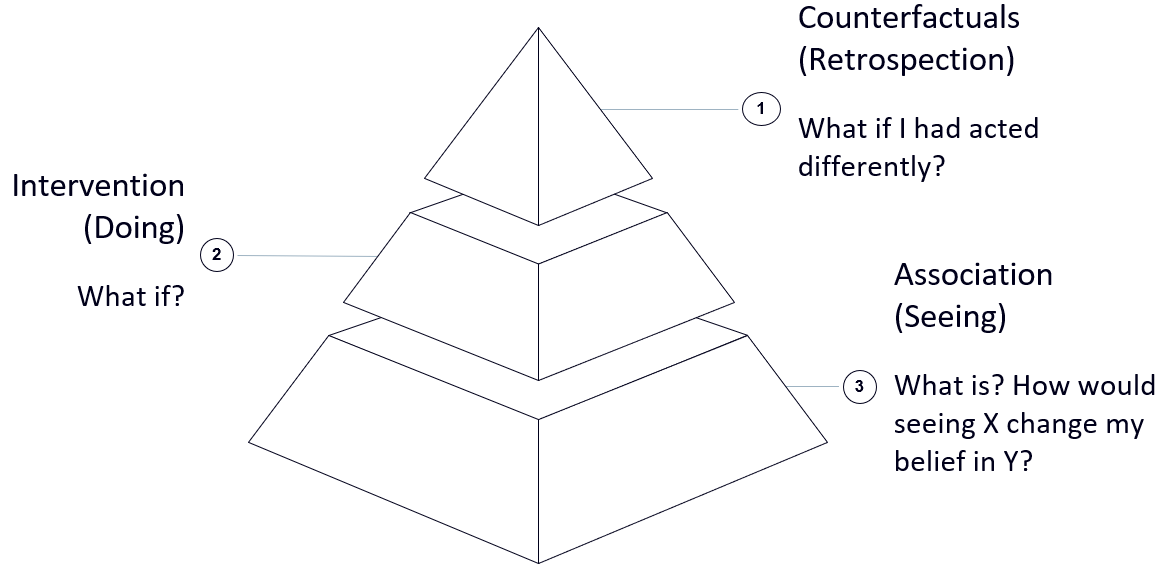
Figure 1: Causality Hierarchy (Image by Author).
Knowledge Graphs
Knowledge Graphs are a type of Graphical Technique commonly used in order to concisely store and retrieve related information from a large amount of data. Knowledge Graphs are currently widely used in applications such as querying information from search engines, e-commerce websites and social networks. Following on our Recommendation System case study outlined before, Knowledge Graphs have been recently applied in causality (Yikun Xian et. al. [1]) in order to generate causal inference based recommendations.
As a simple example, let us consider what happens if we use a search engine in order to find out who Leonard Nimoy is (the actor who played the part of Spock in Star Trek). Once entered our query, the search engine will automatically build a Knowledge Graph similar to the one shown in Figure 2 taking as a starting point our search query and then expanding from it to fetch any related information.
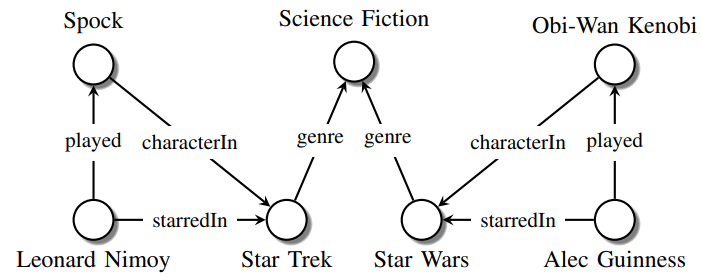
Figure 2: Simple Knowledge Graph. Image reproduced from [2].
One of the most promising applications of Knowledge Graphs, is to create Machine Learning models able to learn from causality. Knowledge Graph Convolutional Networks (KGCN), represents one of the first successful applications in this ambit [3]. Graph Convolutional Networks, are in fact designed to create a vector (embedded) representation of a Knowledge Graph which can then be fed into a Machine Learning model to generate inference paths and provide evidence for the model predictions [4]. KGCN can be potentially used for either supervised or unsupervised tasks (eg. multi-class classification and clustering).
Bayesian Belief Networks
Bayesian Belief Networks are a type of probabilistic model which makes use of simplifying assumptions so that to reliably define connections between different elements and calculate their probabilities relationships efficiently. By analysing interactions between the different elements, we can finally make use of these type of models in order to discover causal relationships. In a Bayesian Network, nodes represent variables while edges report the probabilistic connections between the different elements. A simple example of a three variables Bayesian Belief Network is available in Figure 3.
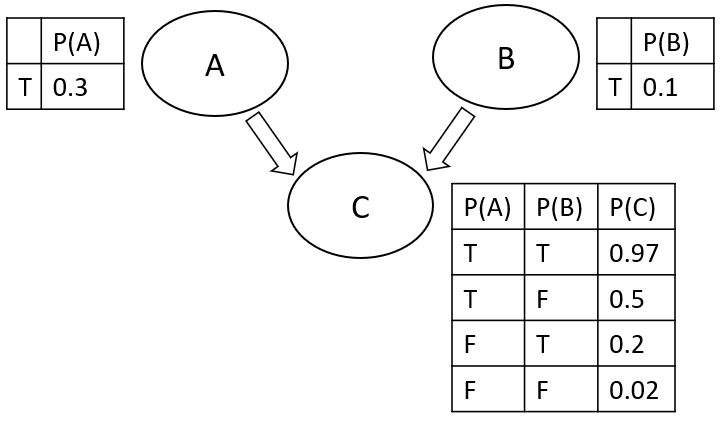
Figure 3: Bayesian Belief Network (Image by Author).
Bayesian Belief Networks, are able to express both conditional dependent and independent variables connections. These type of networks, follow additionally the Markov condition [5] (provided the parents of every node in a network, each node is conditionally independent of their non-descendent nodes). Finally, using Bayes probabilistic approach (Equation 1), we can be able to update the connection probabilities iteratively based on new gathered evidence.

Equation 1: Bayes Rule (Image by Author).
Great research focus by companies such as DeepMind is currently put into using Bayesian Belief Networks as a starting point in order to create Causal Bayesian Networks (CBN) [6]. Causal Bayesian Networks, are nowadays used in order to visually identify and quantitatively measure unfairness patterns in datasets (elements in the data which can lead to Machine Learning models biased towards specific subcategories). Additionally, researches also demonstrated the possibility to use Causal Bayesian Networks in order to identify if not just the data but also the Machine Learning models itself are biased or not towards specific classes [7].
Explainable AI
One of the major trade-offs in nowadays Machine Learning is model performance against complexity. In fact, complex Deep Learning architectures are usually able to perform better in a wide variety of tasks compared to traditional linear classifiers and regression techniques. This trade-off has been analysed in-depth in the 2016 publication “Why should I trust you?” by Ribiero et. al. [8] and led a new trend in AI to focus on interpretability.
Complex and more accurate models are nowadays referred to as Black-boxes. These type of models working progresses are more difficult to comprehend and they are not able to estimate the importance of each feature and how they are related to each other. Some examples of Black Boxes models are neural networks and ensemble models.
On the other hand, simpler and less accurate models such as decision trees and linear regression, are instead regarded as White-boxes and can be much more interpretable. Two of the main measures which can be used in order to estimate the explainability of a model, are the linearity and monotonicity of its response function [9].
Model surrogates
One possible approach which can be used in order to make models more explainable, is to create surrogate versions (approximated versions). This can be done either on a local or global scale.
- Global Surrogate Model: in this situation, we create a linear and monotonic approximation of our original non-linear model which is valid for any possible input. In case, the original model was highly non-linear, then creating a Global Surrogate might lead to poor performances.
- Local Surrogate Model: are typically implemented when trying to approximate highly non-linear models. Using this type of approach, we can, in fact, divide our original feature space into different linear subsections. For each of these sections, can then be created a linear model equivalent approximation (e.g. using decision trees and linear models). Local Surrogate Models, are also commonly referred to as Local Interpretable Model-Agnostic (LIME).
Surrogate models, are trained using the input features and the original model predictions (instead of the ground-truth labels).
In Figure 4, is available a simple example showing how a fitted curve might look like, for a regression task, when using either standard black box models or model surrogate techniques.
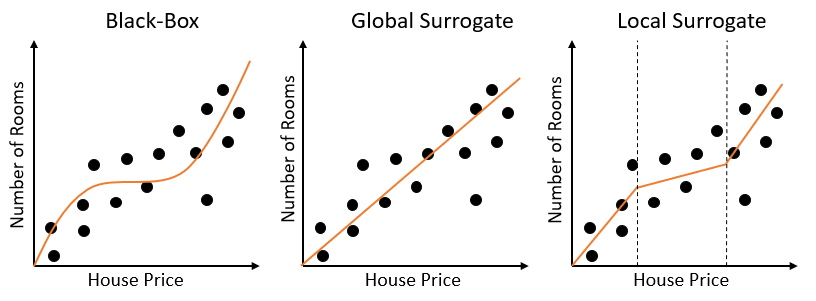
Figure 4: Model Surrogates Example (Image by Author).
Some alternative approaches which can be used in order to make models more explainable are: Feature Importance, Shapley additive explanations (SHAP), Partial Dependence Plots (PDP) and Gradient/Attention-based methods.
Bias in AI
Another key reason why it is important to create Explainable and Causality based Machine Learning models, is to identify and prevent any possible form of bias (e.g. unfair discrimination against any particular class). Bias can potentially arise in fact from either the training dataset itself (e.g. our limited amount of data might not be able to correctly represent the real population distribution) or the model constitution (e.g. our model might unjustifiably prefer one class over the others). Some examples of possible types of bias are: Interaction Bias, Latent Bias and Selection Bias.
Bibliography
[1] Reinforcement Knowledge Graph Reasoning for Explainable Recommendation, Yikun Xian et. al. Accessed: https://arxiv.org/pdf/1906.05237.pdf July 2020.
[2] A Review of Relational Machine Learning for Knowledge Graphs. Maximilian Nickel, Kevin Murphy, Volker Tresp, Evgeniy Gabrilovich. Accessed: https://arxiv.org/pdf/1503.00759.pdf July 2020.
[3] KGCNs: Machine Learning over Knowledge Graphs with TensorFlow. James Fletcher, Grakn Labs. Accessed: https://blog.grakn.ai/kgcns-machine-learning-over-knowledge-graphs-with-tensorflow-a1d3328b8f02 July 2020.
[4] Knowledge Graphs and Causality. Gianmario Spacagna, Vademecum of Practical Data Science. Accessed: https://datasciencevademecum.com/2019/12/19/knowledge-graphs-and-causality/ July 2020.
[5] Introduction to Causal Inference. Peter Spirtes, Department of Philosophy, Carnegie Mellon University. Accessed: http://www.jmlr.org/papers/volume11/spirtes10a/spirtes10a.pdf July 2020.
[6] Causal Bayesian Networks: A flexible tool to enable fairer machine learning. Silvia Chiappa and William Isaac, DeepMind. Accessed: https://deepmind.com/blog/article/Causal_Bayesian_Networks July 2020.
[7] Path-Specific Counterfactual Fairness. Silvia Chiappa and Thomas P. S. Gillam, DeepMind. Accessed: https://arxiv.org/pdf/1802.08139.pdf July 2020.
[8] “Why Should I Trust You?” Explaining the Predictions of Any Classifier. Marco Tulio Ribeiro, University of Washington et. al. Accessed: https://arxiv.org/pdf/1602.04938.pdf July 2020.
[9] Black-box vs. white-box models. Lars Hulstaert, Towards Data Science. Accessed: https://towardsdatascience.com/machine-learning-interpretability-techniques-662c723454f3 July 2020.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
