Contents
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/10644/0*t12C1zhnV1W4p-k2)
Getting Started with Apache Spark
Exploring some of the key concepts associated with Spark, and what defined its success in the Big Data realm
Introduction
One of the main issues that characterized the inception of the internet as we know it today was the inability to scale (e.g. being able to search large amounts of data in a short time, support a constantly varying amount of users without any downtime, etc…).
This was ultimately due to the fact that in an online world new data of varying shapes and sizes is constantly being generated and processed (additional information about Big Data Analysis is available in my previous article).
One of the first approaches taken in order to try to solve this problem was Apache Hadoop (High Availability Distributed Object Oriented Platform). Hadoop is an open-source platform designed in order to break down data jobs into small chunks and distribute them as jobs across a cluster of computing nodes in order to be able to process them in parallel. Hadoop can be broken down into 3 key components:
HDFS (Hadoop Distributed File System): a distributed file system designed for large data support and fault tolerance.
MapReduce: a framework designed in order to facilitate the parallelization of data jobs across a cluster. During the mapping process, the input is taken and processed in key-value pairs which are then passed to a reduce operation used in order to aggregate the output and provide a final result.
YARN (Yet Another Resource Negotiator): to manage the different nodes of the cluster (e.g. schedule jobs, tasks, etc…) and evenly distribute workloads.
Using Hadoop, was therefore possible to process large amounts of data by horizontally scaling our infrastructure (adding more machines) and parallelizing execution. Scaling operations horizontally has in fact become the de facto standard approach in most applications in the past few years due to the slowing down of Moore’s law and the simultaneous reduction in cloud storage costs worldwide.
On the other hand, Hadoop has also many limitations:
Not fully designed to support tasks other than batch processing (e.g. streaming, Machine Learning, etc…)
Difficult to manage and optimize.
An overly verbose API requiring a lot of boilerplate code.
As part of the batching process, intermediate computations are written and then read from disk (therefore causing performance bottlenecks).
In order to try to solve all these limitations, Apache Spark was created.
Apache Spark
Apache Spark started as a research project of Matei Zaharia at UC Berkeley in 2009 and today is recognized as one of the most popular computational engines to process large amounts of data (being orders of magnitude faster than Hadoop MapReduce for certain jobs). Some of the key improvements of Spark over Hadoop are:
A suite of libraries to support different types of workflows (e.g. Spark ML, Structured Streaming, Spark SQL, Graph X).
A highly fault-tolerant and parallel ecosystem.
APIs for multiple programming languages (e.g. Scala, Java, Python, SQL, R). Independently of the language used, the program is then decomposed in bytecode and executed on the workers of the cluster.
In-memory storage for intermediate computations.
Focus on computation (e.g. Hadoop included both a computation and storage system instead Spark is open for almost any storage option).
A Spark application can be broken down into many different components (Figure 1). A driver is used in order to instantiate a Spark session and use it in order to interact with the different components of the cluster (e.g. cluster manager and executors). As part of a program execution, the driver is then responsible to request the necessary resources from the cluster manager (e.g. memory, CPUs) in order to let the executors (e.g. Java Virtual Machines) carry on their tasks and communicate directly with the executors to optimize the execution. Spark is currently able to support 4 different types of cluster managers: standalone, Hadoop YARN, Apache Mesos and Kubernetes.
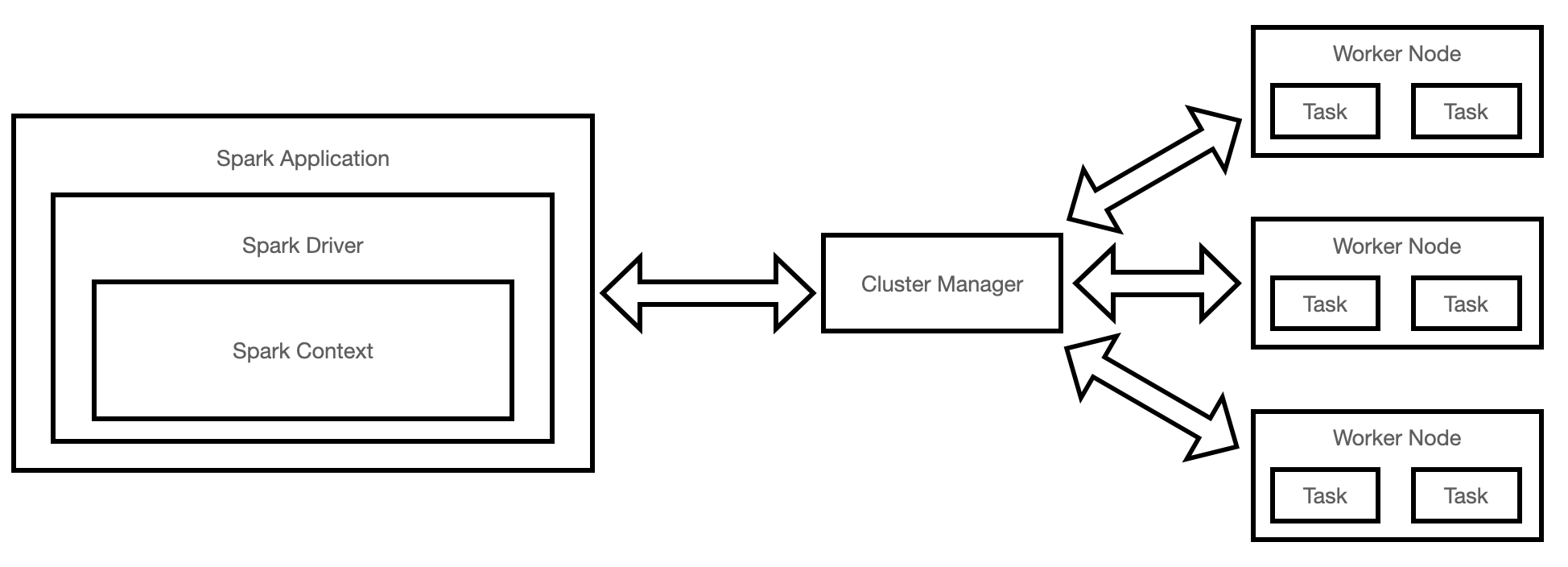 Figure 1: Apache Spark Architecture (Image by Author).
Figure 1: Apache Spark Architecture (Image by Author).
Throughout the process, the data is stored as partitions, and executors are preferably assigned tasks that require processing data that is closest to them (to minimize network bandwidth).
There are 2 types of operations that Spark can perform on data: transformations and actions. Transformations create a new Spark data frame without altering the original one and are always evaluated lazily (they are not executed immediately but remembered as a part of a lineage). This makes then possible to create a directed acyclic graph (DAG) of transformations which can then be enhanced to run in the most efficient way taking advantage of Spark Catalyst optimizer rule-based and cost-based optimizations. Having a lineage of transformations and immutable data frames can then enable Spark to create a highly fault-tolerant system. Transformations are finally executed whenever an action is called.
Transformations can additionally be divided into narrow or wide. Narrow transformations take a single input partition and return a single output partition (e.g. filter operation), while wide transformations use instead multiple partitions and require re-shuffling of the data (e.g. groupby operation).
Over the past few years, different forms of structures have been developed on top of the Spark API in order to make it easier to develop in Spark. RDDs (Resilient Distributed Dataset) are the most basic form of abstraction in Spark and have nowadays been mainly replaced by Spark’s Structured APIs (Dataset, Dataframe APIs) equivalent commands. In fact, Spark Structured APIs are completely built on top of RDDs and have been designed in order to provide easy-to-use pre-optimized code for the majority of the most common tasks in the data processing realm. Additionally, Spark makes also possible to create custom functions through UDFs (User Defined Functions). Spark UDFs can be written in different programming languages (e.g. Python, Java, Scala, etc…), although it is currently recommended to write UDFs in Java or Scala since it can provide overall greater performance (e.g. UDFs are like black boxes for the Catalyst Optimizer and therefore if written in Python can’t be fully optimized).
Finally, Spark makes also possible to run Machine Learning workflows using their Spark ML library (Figure 2). This library can be divided into 4 key constituents:
Transformers: are mainly used to perform data engineering/pre-processing tasks (e.g. scaling, feature selection, etc…) and they just apply rule-based transformations (there is no learning from data). They take a data frame as input and return a new data frame.
Estimators: learn parameters from the data and return a trained ML model (which is a Transformer).
Pipeline: organizes a sequence of Transformers and Estimators in a single object.
Evaluators: used in order to assess our Machine Learning models through various classification, regression, etc… metrics.
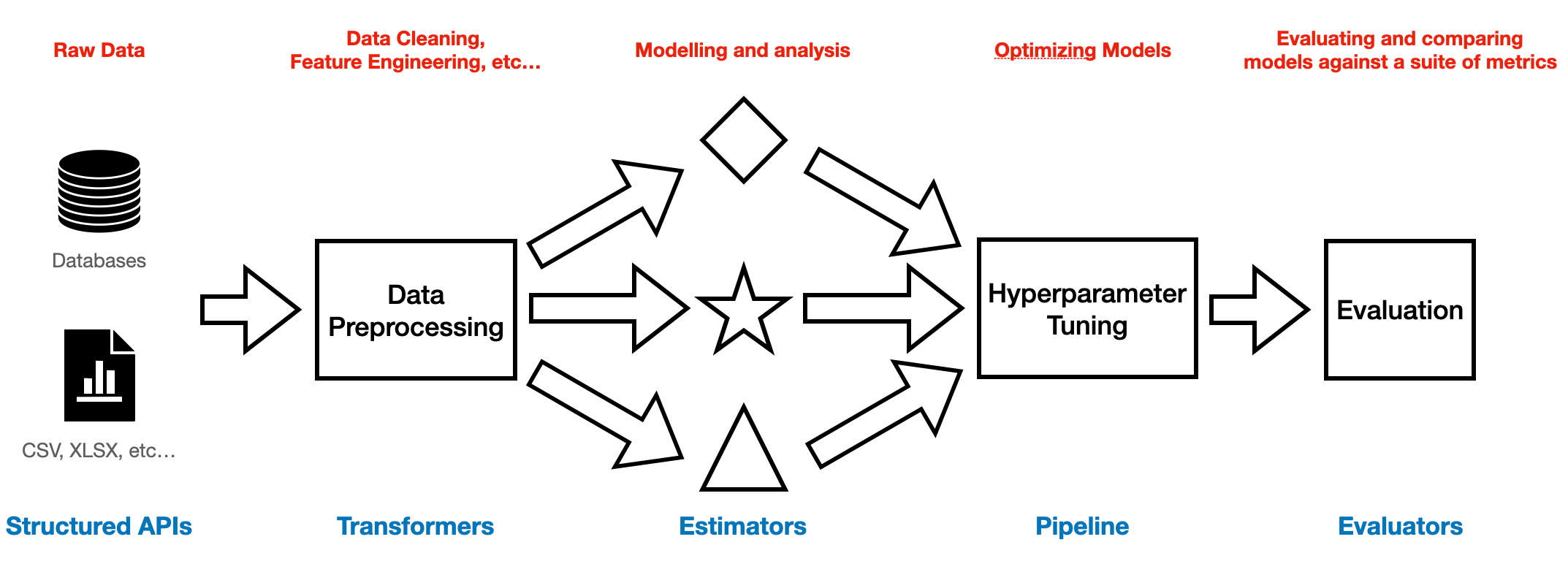 Figure 2: Spark ML Workflow (Image by Author).
Figure 2: Spark ML Workflow (Image by Author).
Additionally, Spark ML can be integrated with various other open source packages such as Hyperopt, Horovod, MLFlow, etc… in order to provide a complete user experience.
Conclusion
Overall, Apache Spark is currently one of the most popular technologies used in the industry in order to handle big data, supported by companies such as Databricks and Palantir. Thanks to recent additions to the ecosystem, Spark is also now becoming also more and more relevant for traditional Data Science users (e.g. Pandas API on Spark), making it one of the most interesting technologies to learn.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
