Contents
Photo by Alexander Hafemann on Unsplash
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/5000/0*uJziYH7WIp3mZhPX)
Introduction to Apache Iceberg
Exploring Apache Iceberg benefits/drawbacks and how it can be used to build your own Lakehouse.
Introduction
Thanks to the advent of Data Lakes easily accessible through cloud providers such as GCP, Azure, and AWS, it has been possible for more and more organizations to cheaply store their unstructured data. Although Data Lakes come with many limitations such as:
Inconsistent reads can happen when mixing batch and streaming or appending new data.
Fine-grained modification of existing data can become complex (e.g. to meet GDPR requirements)
Performance degradation when handling millions of small files.
No ACID (Atomicity, Consistency, Isolation, Durability) transaction support.
No schema enforcement/evolution.
To try to alleviate these issues, Apache Iceberg was ideated by Nextflix in 2017. Apache Iceberg is a table format able to provide an additional layer of abstraction to support ACID transactions, time travel, etc.. while working with various types of data sources and workloads. The main objective of a table format is to define a protocol on how to best manage and organize all the files composing a table. Apart from Apache Iceberg, other currently popular open table formats are Hudi and Delta Lake.
For example, Apache Iceberg and Delta Lake mostly have the same characteristics although for example, Iceberg can support also other file formats like ORC and Avro. Delta Lake on the other hand is currently heavily supported by Databricks and the open-source community and able to provide a greater variety of APIs (Figure 1).
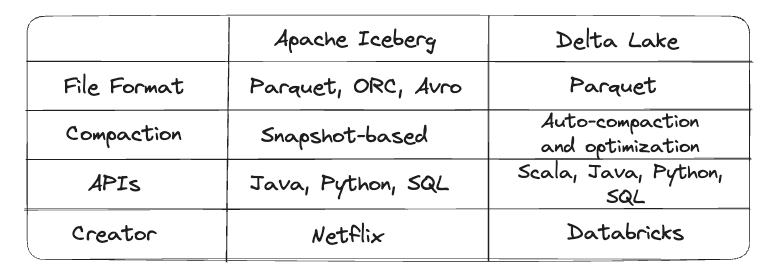
Figure 1: Apache Iceberg vs Delta Lake (Image by Author).
Throughout the years, Apache Iceberg has been open-sourced by Nexflix and many other companies such as SnowFlake and Dremio have decided to invest in the project.
Each Apache Iceberg table follows a 3 layers architecture:
Iceberg Catalog
Metadata Layer (with metadata files, manifest lists, and manifest files)
Data Layer
The catalog is used to map table names to locations and must be able to support atomic operations to update referenced pointers if needed. The Metadata Layer stores instead all the enriching information about the constituent files for every different snapshot/transaction. For example, at this layer are stored information about the table schema, configurations for the partitioning, etc… The Data Layer is finally associated with the raw data files.
If you are interested in finding out more about Apache Iceberg architecture, additional information can be found in this article.
Advantages
Some of the key advantages of Apache Iceberg include:
Schema evolution: ability to add, drop, rename, reorder, and update data seamlessly without unforeseen side effects (all done without needing to rewrite the table in full).
Time Travel: quickly switch between different table versions and compare changes. This makes also possible to rollback to previous table versions in case errors are introduced.
Hidden Partitioning: handling automatically partitioning to skip unnecessary files and speed up query execution.
Disadvantages
Matadata: in order to unlock many of Apache Iceberg capabilities, additional metadata is used extensively (which can create a storage overhead).
Learning curve: to make the best out of Apache Iceberg good domain knowledge is required (this can be partially handled out of the box if using managed tools like Dremio or Snowflake).
Data Lakehouse
Apache Iceberg can then form the foundation for an organization to build its own Data Lakehouse. The key idea behind a Lakehouse is to be able to take the best of a Data Lake and a Data Warehouse. Data Lakes can in fact provide a lot of flexibility (e.g. handle structured and unstructured data) and low storage cost, on the other hand, Data Warehouses can provide really good query performance and ACID guarantees.
In order to construct a Data Lakehouse, we need 5 key components: Storage Layer, File Format, Table Format, Catalog, Lakehouse Engine (Figure 2). For each of these components, we can then be free to pick any technology we best see fit for our use case. For example, as a computational engine, we can pick anything between Spark, Flink, Trino, Impala, Dremio, etc…
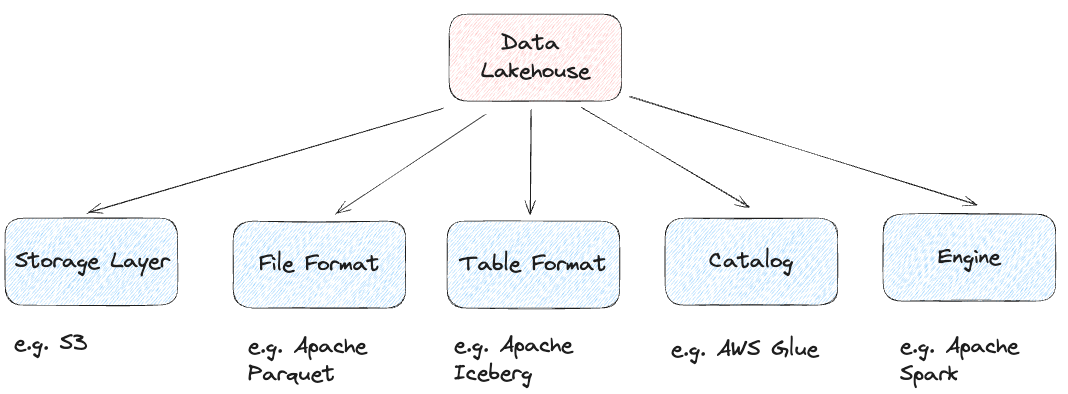
Figure 2: Data Lakehouse Components (Image by Author).
Following this approach, organizations would not be required anymore to maintain two different systems:
Data Lake to stage raw and unstructured data which can either be directly used to power Machine Learning and Deep Learning use cases or sent to a Data Warehouse after ETL refinement.
Data Warehouse to power business intelligence and reporting operations given its ACID reliability and good query performance.
In this scenario, the Data Lakehouse could finally act as a “Single Source of Truth” for an organization preventing unnecessary data duplication and increasing business users’ trust in the provided data.
Finally, to empower the different business units of large organizations and create “data as a product” the Data Lakehouse could then be further structured to follow a Data Mesh approach refined on the specific business domains.
Conclusion
To sum up, Apache Iceberg can be a great tool to use in order to modernize your data infrastructure although it cannot be considered a catch-all solution for all your possible use cases. It was in fact designed to work best with large amounts of data and distributed systems. It would therefore provide more overhead than benefits if working with small datasets or trying to perform some real-time latency operations.
If you are interested in learning more about how Apache Spark can be used as a computer engine to power your Data Lakehouse you can find additional information in this article.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
